Clay Shirky's "Ontology is overrated" - good read
One reason Google was adopted so quickly when it came along is that Google understood there is no shelf, and that there is no file system. Google can decide what goes with what after hearing from the user, rather than trying to predict in advance what it is you need to know.
Let's say I need every Web page with the word "obstreperous" and "Minnesota" in it. You can't ask a cataloguer in advance to say "Well, that's going to be a useful category, we should encode that in advance." Instead, what the cataloguer is going to say is, "Obstreperous plus Minnesota! Forget it, we're not going to optimize for one-offs like that." Google, on the other hand, says, "Who cares? We're not going to tell the user what to do, because the link structure is more complex than we can read, except in response to a user query."
Browse versus search is a radical increase in the trust we put in link infrastructure, and in the degree of power derived from that link structure. Browse says the people making the ontology, the people doing the categorization, have the responsibility to organize the world in advance. Given this requirement, the views of the catalogers necessarily override the user's needs and the user's view of the world. If you want something that hasn't been categorized in the way you think about it, you're out of luck.
The search paradigm says the reverse. It says nobody gets to tell you in advance what it is you need. Search says that, at the moment that you are looking for it, we will do our best to service it based on this link structure, because we believe we can build a world where we don't need the hierarchy to coexist with the link structure.
Information architecture in claymation

This is the
winner of the Explain IA award.
Go watch! Be careful of the bleeped language,
though. Yes, bleeps seem to be required in the
explanation
The Death of taxonomies?
The Death of Taxonomies, revisited
Earlier this year I caused quite a stir when I predicted the death of taxonomies. Taxonomists worldwide told me I was an idiot, nuts, completely delusional. Some were deeply concerned that their jobs were threatened, as if employers would change org charts based on my prediction. Others secretly told me they agreed.
Of course, as so often happens in these dark days of 140-character tweets, my prediction was often taken out of context. I had predicted the death of traditional, monolithic, and single-hierarchy taxonomies, as well as the death of what I’d call the typical turn-of-the-21st-century taxonomy project (which I did dozens of times, as a former taxonomist), where librarians and/or linguists spend a few months in an organization determining how enterprise content should be categorized, so content technology could use it optimally. This project would usually be followed by an even longer period when people would admire the taxonomy, nod knowingly, saying “that’s exactly what we need!” - but not tag anything, despite the roadmap and project plan saying they should.
As 2010 fast approaches, I’ve never been more sure of my prediction. Metadata continues to be vital, but technology is constantly getting better at mining and organizing it. As an example, this week I visited three organizations in Paris using Sinequa (one of the vendors we evaluate in our Search & Information Access research) on their intranets. In an approach similar to Endeca’s, entity extraction and semantic analysis create multi-faceted categorizations by people, country, city, language, companies, and other topics. Most of the content was unstructured; no taxonomy or tagging projects were undertaken.
Read more....
100 words every high school graduate should know
“The words we suggest,” says senior editor Steven Kleinedler, “are not meant to be exhaustive but are a benchmark against which graduates and their parents can measure themselves. If you are able to use these words correctly, you are likely to have a superior command of the language.”
The following is the entire list of 100 words Every High School Graduate Should Know:
abjure
abrogate
abstemious
acumen
antebellum
auspicious
belie
bellicose
bowdlerize
chicanery
chromosome
churlish
circumlocution
circumnavigate
Okay, you have to go to the website for the full list. But I love that "feckless" and "moiety" made the list, and I am happy to see "taxonomy" on it!
Wikipedia as controlled vocabulary

Merlin Mann on getting things done
Worth listening to here.
Taxonomies and tags are political, or #Amazonfail
Complaints, firestorms on Twitter, blog posts, and general mayhem ensued. Many people thought it was an act of out and out bias, especially since gay marriage in the states has been a big newsmaker in this last month. Authors asked Amazon what was going on, and received a tepid response. Evidently the powers that be at Amazon had decided to no longer display books tagged with the "adult" tag in their rankings anymore. And somehow, this "adult" tag included books like Heather has Two Mommies and Lady Chatterley's Lover, not just adult books. It meant that if you searched on "homosexuality", your searches would only reveal anti-homosexuality books and items. Several blogs took screen captures and posted them. Many people went into Amazon's book listings and started tagging books with #amazonfail. User tagging as a protest tool! Twitter posts quickly spread with the #amazonfail tag as well.
After reading a ton of articles and postings about this mess, I think I agree with Patrick at Making Light:
I’d bet lunch that the sequence of events, in its simplest form, went something like this:
(1) Sometime in the middle-distance past—maybe a couple of months ago, maybe a year, it doesn’t matter—somebody decided that it would be a good idea to make sure that works of straight-out pornography (or, for that matter, sex toys) didn’t inadvertently show up as the top result for innocuous search queries. (The many ways that this could happen are left as an exercise for Making Light’s commentariat.) A policy was promulgated that “adult” items would be removed from the sales rankings and thus rendered invisible to general search.
(2) Sometime more recently, an entirely different group of people were given the task of deciding what things for sale on Amazon should be tagged “adult,” but in the journey from one department to another, and from one level of the hierarchy to another, the directive mutated from “let’s discreetly unrank the really raunchy stuff” to “we’d better be careful to put an ‘adult’ tag on anything that could imaginably offend anyone.” Indeed, as Teresa pointed out, it’s entirely possible that someone used a canned list of “adult” titles supplied from outside, something analogous to the lists of URLs sold by “net nanny” outfits, which would account for the newly-unranked status of works like Lady Chatterley’s Lover. (As one net commenter observed, “What is this, 1928?”)
I have found when doing taxonomy that it is an activity with almost no neutral ground. Every decision has its opponents, and you have to build consensus for a particular worldview when you are working with groups who see the world differently, and that's nearly every group of more than two people. I was working in a relatively calm area like PC hardware or software tasks, where you would think a printer and a monitor are not the same category of item, and yet I heard arguments that were valid showing me why they were the same! "It depends," as we always say about indexing.
Things are starting to get fixed. Some recent searches under homosexuality on Amazon were starting to show more normal results, so I think the #amazonfail tagging effort has had some effect and Amazon is doing something about this, after their feeble first response. The Seattle PI has a response from Amazon's Drew Herdener:
This is an embarrassing and ham-fisted cataloging error for a company that prides itself on offering complete selection.
It has been misreported that the issue was limited to Gay & Lesbian themed titles – in fact, it impacted 57,310 books in a number of broad categories such as Health, Mind & Body, Reproductive & Sexual Medicine, and Erotica. This problem impacted books not just in the United States but globally. It affected not just sales rank but also had the effect of removing the books from Amazon's main product search.
Many books have now been fixed and we're in the process of fixing the remainder as quickly as possible, and we intend to implement new measures to make this kind of accident less likely to occur in the future.
Amazon does need to look at its taxonomy structures and labeling, and see where they might be failing. You cannot let machine algorithms replace human sensibility. I think Amazon is importing tags from publishers, and probably importing taxonomies. At a session years ago I heard from an employee that they let all of their fact-checking people go, and rely on users and publishers to supply correct and corrected data on all of their bibliographic information. It saved them 400 jobs. Libraries I knew had stopped their subscriptions to Books In Print, thinking Amazon would be easier and faster and just as good, not realizing that it is full of errors until corrected. We have all seen examples of wrong covers for books, or indexes for the first edition showing up in the second edition's listings. I would bet they are relying on publishers for taxonomic structures as well, but I don't know for sure. Probably piecemeal, using them in places, finetuning them in others.
As Laura Dawson says:
I've done so much taxonomy work, both for Muze and BN.com - and my colleagues and I have all agonized over the political decisions we've had to make because in a taxonomy you have to articulate concepts and arrange them. Like staying-awake-at-night agonizing, because these articulations and arrangements either bring books to light or tuck them away where few can find them, depending. (Richard Nash also makes a great point up this same alley.)
And it's worth getting upset about. What happened at Amazon is the result of dozens of small decisions about how to name things and the structure of those names - whether the decisions were made by people at Amazon or they were importing other companies' taxonomies (probably both) or using semantics to create algorithms. Shirky is right in that it probably wasn't a person or group of people deciding that they didn't like gay people that day. But (as Richard points out) it was the result of heteronormative thinking creating search rules that ultimately resulted in...#amazonfail.
What taxonomizing teaches you is that no worldview is neutral, and the best you can hope for is to keep trying to reach in that direction. Detangling what happened at Amazon is compounded by the fact that they aren't talking to anyone, but it appears to be a compilation of complacent taxonomizing, linking certain concepts to the theme "adult", imposing some sort of filter on the "adult" titles (without realizing what "adult" meant in terms of the terms that linked to it) in a misguided effort to make explicit books less visible, not fully investigating the problem when it first came to Amazon's attention (but dismissing it as a "policy" decision, which is most likely never was in the first place), and now not really responding effectively. Probably because those in charge of responding really have no idea how it happened.
Laura wrote that last bit before Amazon's second response.
Taxonomies and tags are political. Indexing is political. Labeling structures are political. So I wonder what tags I'll use to categorize this post - ;-)
If you want to read up on what happened, and many people's responses, here's a list of blog postings:
Laura Dawson
Clay Shirky
Mary Hodder
Richard Eoin Nash
Jane at Dear Author
Evir connection visualizations
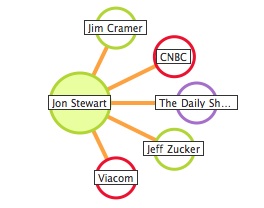
Nice representation of related terms, narrow terms, and identifying connective words. It's not a strict taxonomy, which would label the connections with broader, narrow, or other identification of the relationships, just showing relationships.
Bruce Sterling on tagging and Web 2.0
Let's look at a few of these Web 2.0 principles and practices.
"Tagging not taxonomy." Okay, I love folksonomy, but I don't think it's gone very far. There have been books written about how ambient searchability through folksonomy destroys the need for any solid taxonomy. Not really. The reality is that we don't have a choice, because we have no conceivable taxonomy that can catalog the avalanche of stuff on the Web. We have no army of human clerks remotely able to tackle that work. We don't even have permanent reference sites where we can put data so that we can taxonomize it....
"Dynamic content." Okay, content is a stable substance that is put inside a container. It's stored in there: that's why you put it inside. If it is dynamically flowing through the container, that's not a container. That is a pipe. I really like dynamic flowing pipes, but since they're not containers, you can't freakin' label them!
There's a lot more, about the next thing, which he calls the Transitional Web. Worth the read.
A taxonomy of messiness

Linde Brocato turned me on to A Perfect Mess by Eric Abrahamson and David Freedman. Here's the taxonomy of messes:
Types of Mess:
Clutter
Mixture
Time sprawl
Improvisation
Inconsistency
Blur
Noise
Distraction
Bounce
Convolution
Inclusion
Distortion
The authors also propose that mess can be categorized by:
Width
Depth
Intensity
There's something very satisfying about classifying mess, or messing up classifications. A good read - recommended!
The death of taxonomy?
On this
first day of 2009, I thought I’d take a moment to
reflect on the CMS Watch list of predictions for
2009. Getting big play in the top 3 is “Taxonomies
are dead. Long live metadata!”
"With social computing coming to the fore, it’s never
been more obvious that everyone does not, and will
never, categorize things in the same way. It doesn’t
even matter what’s correct anymore… I will assert
that the days of the traditional, definitive, and
single-hierarchy taxonomy are long behind us."
I think that this is accurate — insofar as it uses
the traditional, definitive and single-dimension
definition of taxonomy that ought to be left in the
dust along with corded telephones and dot matrix
printers. I mean, I can’t even remember ever building
a taxonomy that was meant to be traditional or had a
single-hierarchy.
The term “taxonomy” has grown to mean so much more
than this… We use taxonomy in a very broad sense -
suggesting that all metadata comes from the taxonomy.
Everything is about classification and structure.
Certainly “taxonomy” has become an abused term. They
say taxonomy when they want their information world
to be a better place. There is a comforting, ordered
ring to the term. It sets all things in the world in
their proper place.
There's a lot more Stephanie talks about, how business people don't get metadata, and how the term taxonomy is evolving, not dying - I highly recommend reading the post and the blog when you can! There are a lot of great articles in the archives as well.